
对于训练后的研究人员来说,印象、提示和氛围是极为重要的信号,这些因素能够促使用户转向其他模型作为日常使用的主要工具。目前,三大领先实验室 OpenAI、Anthropic 和 Google 的模型水平相近,用户意识到他们可以选择其他选项。早在 Claude 3.5 发布之前,许多人就因其卓越的编码能力而转向 Claude。尽管 Claude 3 的表现也不错,但这并不足以让我放弃 ChatGPT。
当模型能力长期停滞时,评估其对用户的实用性变得更加简单。Claude 3.5 在可靠性上超越 ChatGPT,满足了我的需求,同时我仍然使用 GPT-4 而非 GPT-4o,这使得我更容易开始使用 Claude 3.5。
Claude 3.5 版本在多个小细节上进行了优化,以更好地服务于成功的模型——更快、更清晰、更一致,这使得蒸馏成为当今顶级实验室的流行技术。
除了基本指标和吞吐量外,Anthropic 的模型始终给人一种个性鲜明的感觉,这正是我所喜爱的。这种风格可能源于专注而有效的微调,团队中的每个人都对模型的期望有着清晰的共识。
我们最接近 Anthropic 模型规范的理解,便是听他们的对齐负责人之一 Amanda Askell 讨论“模型的个性应该是什么”,或阅读模型的系统提示。Claude 模型专注于乐于助人、慈善和诚实,这一点非常突出。相比之下,OpenAI 的模型规范则显得相对枯燥,强调遵守规则。
在 Claude 2.1 发布时,Anthropic 试图通过减少模型对未知问题的回答来提升模型的诚实性,但这引发了不少反对意见。增加拒绝回答的选项吸引了许多人工智能评论员。事后看来,这正是我们现在喜欢 Claude 3.5 的原因——它能够准确遵循我的指示。我怀疑这与模型对自身知识的认知密切相关。
人们普遍认为,这些收益大部分(包括 OpenAI 的进展)源于后训练方法的改进,例如从人类反馈中进行强化学习 (RLHF)。我赞赏 Anthropic 对个性特征的重视,并理解这如何将我们从模型中获得的信息情境化。在我最近关于 RLHF 如何运作的文章中,我解释了这一点的重要性:
风格是人类价值的源泉,这就是为什么重述故事可以产生新的畅销书(例如《人类简史》),并且它是继续推进我们的知识生态系统的基本组成部分。风格与信息本身息息相关。
您可以通过以下方式了解 Claude 3.5 的风格:
- 它更像助手,在回答简单问题或请求时询问“我应该做 X 吗”。
- 语气专注,用词特别,与 ChatGPT 近期模型有时不必要的冗长形成鲜明对比。我在纠正问题中的拼写错误时,注意到了一些更有趣的填充词,比如“这很有道理”。
- 当被明确要求解决任务而不是在文本中进行情境化时,会更快地删除所有占位符文本。
在使用 Claude 一周左右的时间里,我发现一些让 ChatGPT 用户感到烦恼的失败模式(例如系统在询问输入的图片时尝试生成图片,或在文本答案中添加“你的代码”)并没有困扰到我。从这个角度来看,Claude 的学习曲线似乎更短。对我来说,正确使用 ChatGPT 需要做很多工作,比如“不要喋喋不休”或正确格式化提示,而我将所有内容交给 Claude,通常都能成功。
更清晰地讲,我认为 Claude 现在就是智能助手,它无需额外信息就能完成我们想要做的事情。这很有趣,但并没有试图用“人工智能应该是什么样子”的答案来打动习惯了 ChatGPT 的人。阻碍 Claude 发展的因素是产品功能和完善程度。
产品优先级
许多人批评 Anthropic 的用户界面(以及其他产品功能)不如 ChatGPT,但实际上,他们将设计与执行混为一谈。对我来说,Claude 的界面更简洁、更直观,但确实缺少一些人们可能习惯于 ChatGPT 的功能。首先,这是 Claude 的界面。
我发现 ChatGPT 在空间利用方面做得更好,但将文本框放在最前面和中间是让人们使用它的最简单方法,谷歌一直都是这样做的。
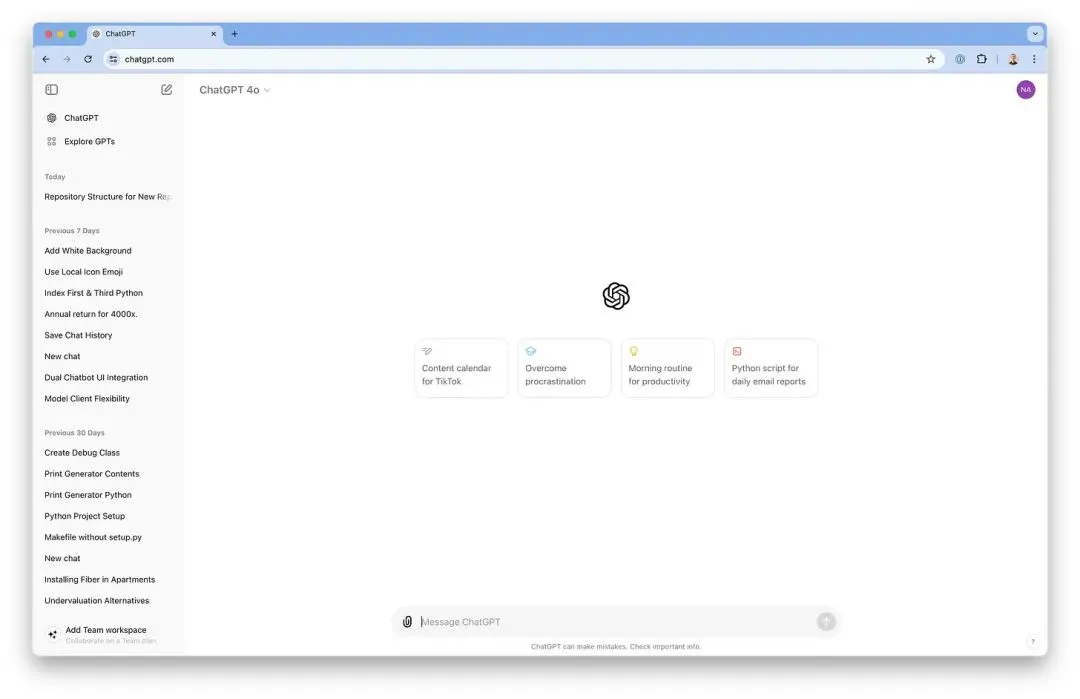
Claude 生成的信息密度也高于 ChatGPT(ChatGPT 为他们自己的一个例子生成了一个非常长的答案,这已经够疯狂了)。
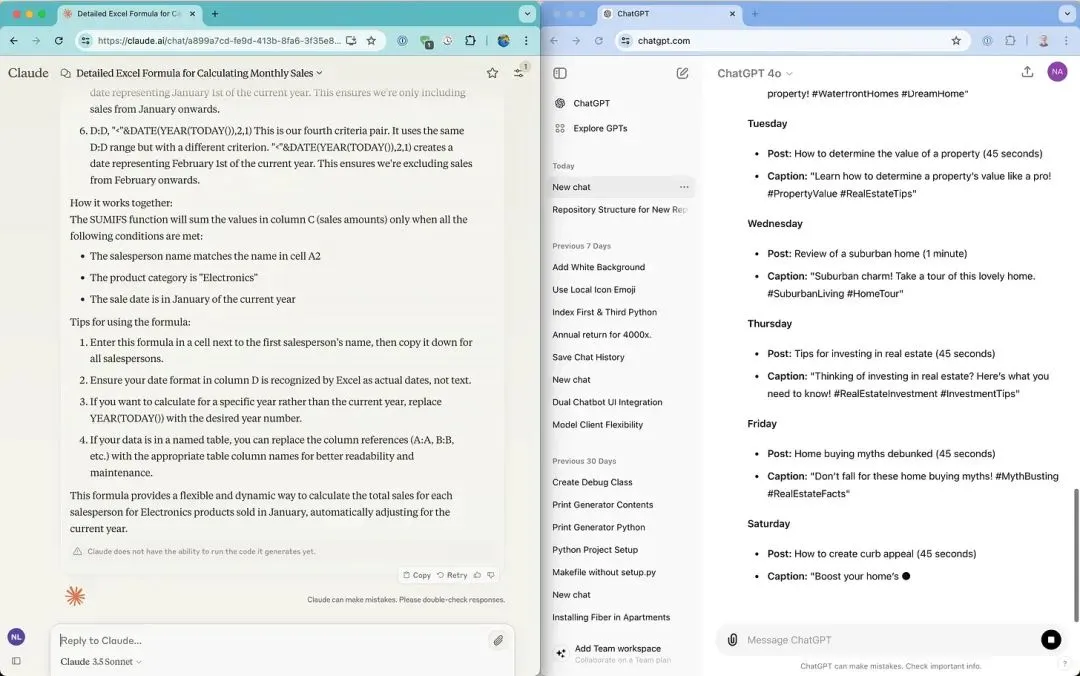
Claude 和 ChatGPT 的 iOS 应用程序反映了 Web 应用程序的特点。以下是它们的比较。
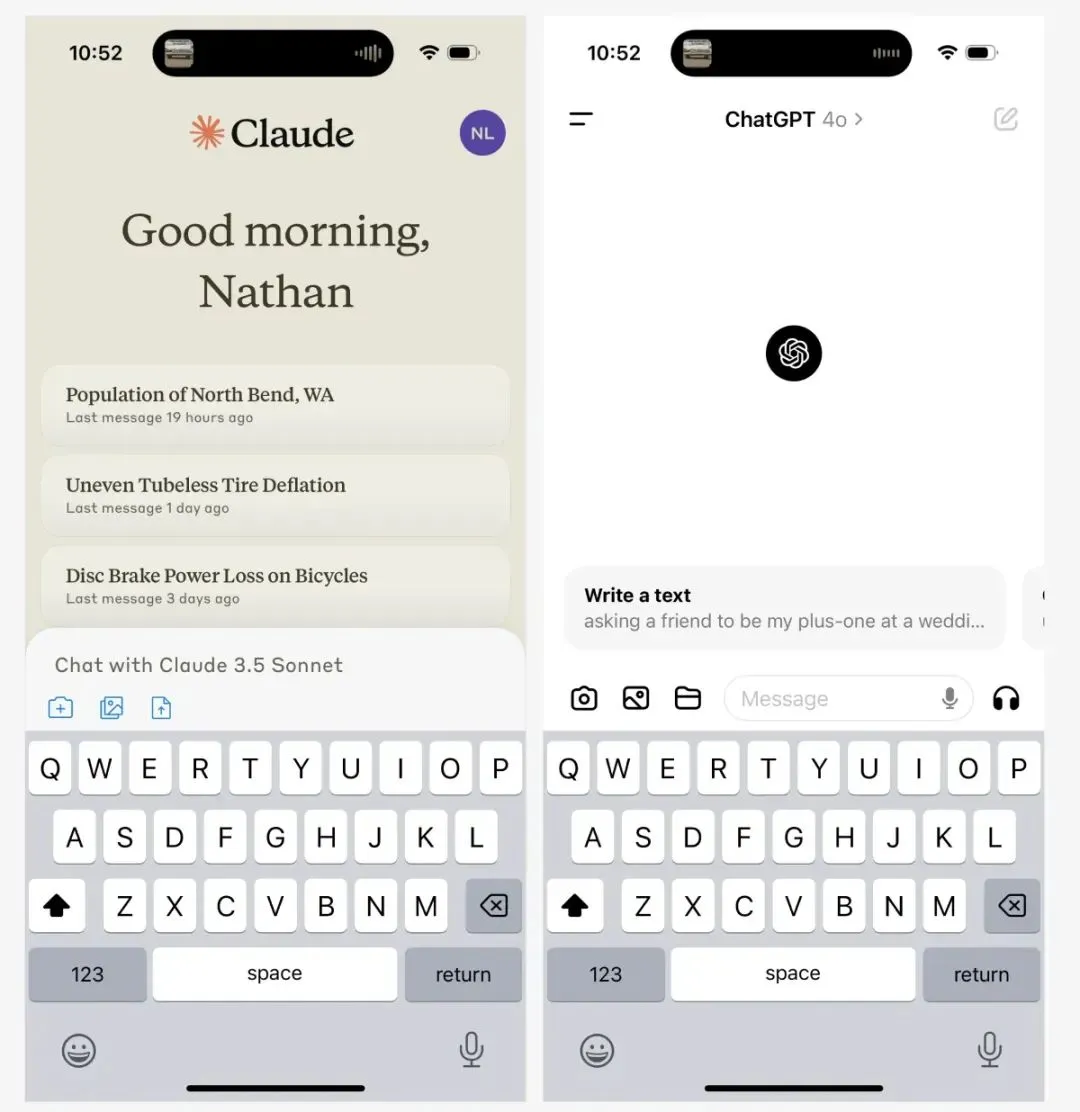
使用 Claude 时,我失去了一些图像生成功能,也无法轻松运行代码,但对我来说,好处仍然大于坏处。无论如何,Anthropic 似乎非常接近添加许多这些功能,而 Artifacts 是 v0。
在这次对话中缺失的环节是谷歌,我在分析大型文件(如完整的播客剧集)时使用它来生成章节和节目笔记。我在研究这篇文章时发现了 Gemini 的新应用页面,但出于某种原因,我以为我应该使用 Google AI Studio,它远远落后于其他所有应用。我的困惑可能并非孤例,这反映出谷歌在人工智能竞赛中启动时有点慢和混乱。他们现在做得更好了,但必须纠正以前缺乏清晰度的问题。
RLHF 的巅峰?
考虑到我个人可能从中受益,我很容易描绘出 RLHF 等后训练方法对人们使用的先进模型越来越重要的说法,但这有点误导。鉴于 RLHF 等方法主要用于从基础模型中挖掘性能潜力,因此很自然地,随着我们逐渐接近这一代基于计算基础设施的模型的末期,后训练在影响力和文化意识方面达到顶峰——至少在这个模型周期中是如此。
事实上,当 GPT-5 和 Ultra/Opus 类模型以快速和自由的推理方式发布到世人面前时,讨论将再次回到数据和扩展上。数据是这里唯一不变的东西,大多数工业训练后收益可能来自精心策划的用户关心的提示数据。
越来越多地,我们过去在大规模预训练后保留用于指令微调的数据集现在被用于“后期预训练”,为模型提供指令遵循的一般概念。随着我们更好地了解人们今天如何使用模型的重要偏好数据集,我们将扩大它们并将其纳入预训练中。RLHF 始终是一个成功的工具,因为它可以适应新的需求并将其纳入模型中。我不认为这是用户看到的大多数功能的来源。
有关 Claude 3.5 的更多信息,您可以查看 野卡 | 一分钟注册,轻松订阅海外线上服务。从 Scale AI 到 ChatBotArena,Claude 在大多数排行榜上都名列第一或接近第一。