北京时间2月16日凌晨,OpenAI 正式发布了其最新的文本到视频生成模型 Sora,标志着其在视频生成领域的加入,紧随 Runway、Pika、谷歌和 Meta 之后。
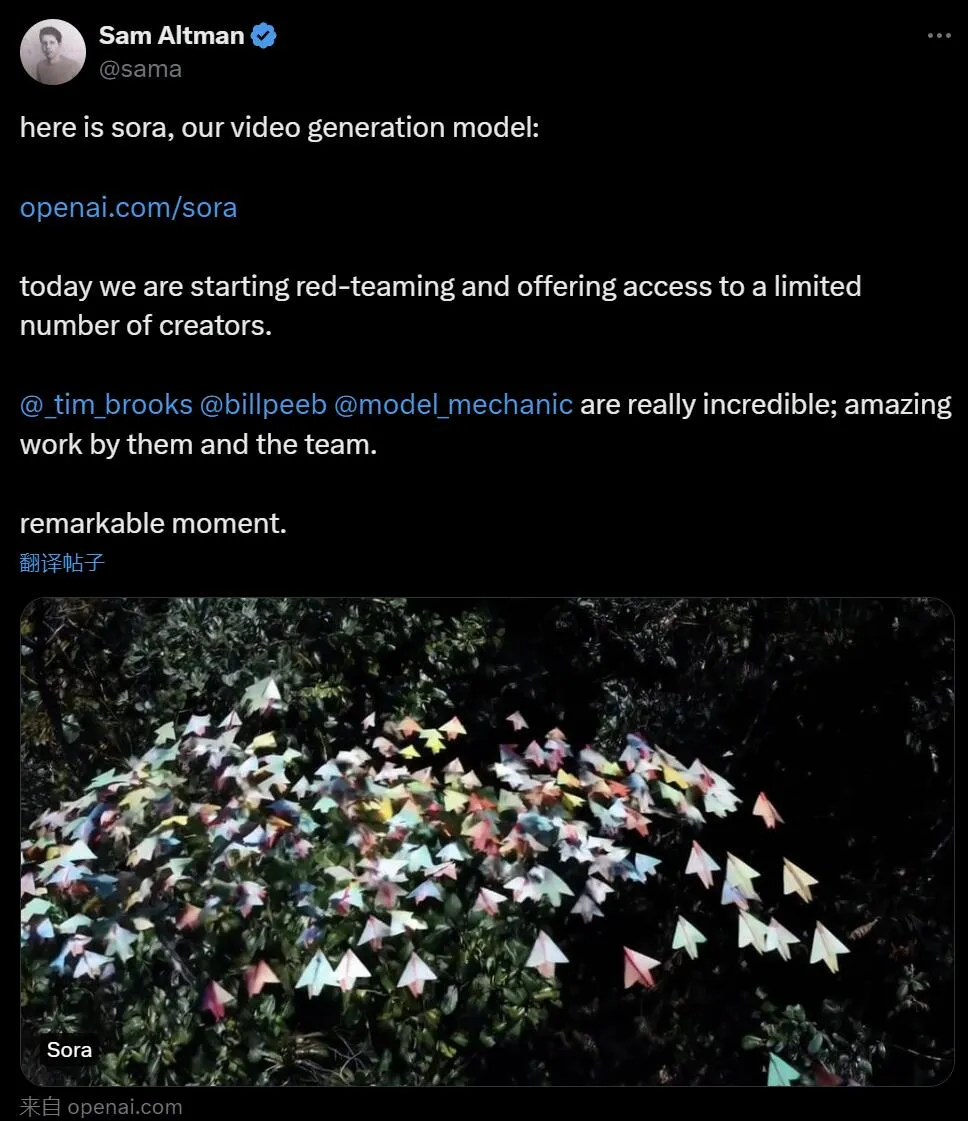

在山姆·奥特曼的消息发布后,OpenAI 工程师展示的 AI 生成视频效果引发了广泛关注,许多人感叹:好莱坞的时代是否已经结束?
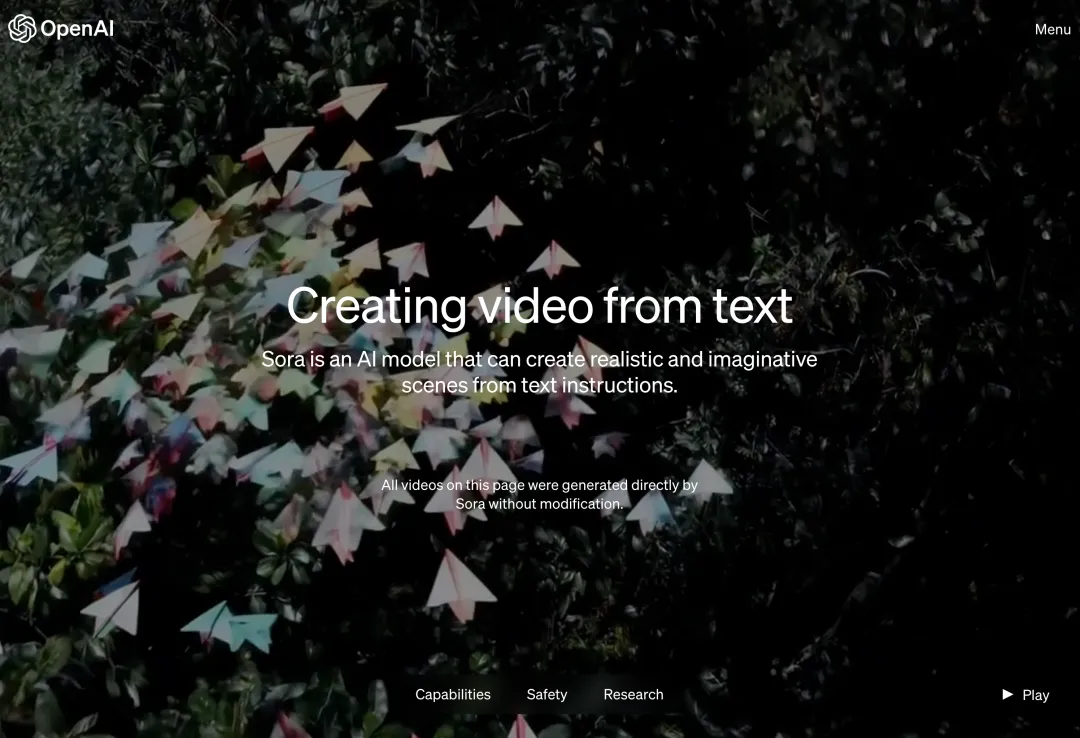
OpenAI 声称,Sora 能够根据简短或详细的描述,甚至一张静态图片,生成类似电影的 1080p 场景,场景中包含多个角色、不同类型的动作和丰富的背景细节。
Sora的独特之处
Sora 在语言理解方面表现出色,能够准确解析用户的提示,并生成生动的角色以表达丰富的情感。此外,Sora 不仅能理解用户的要求,还能感知物理世界中的存在方式。
在官方博客中,OpenAI 提供了多个 Sora 生成的视频示例,展示了其令人印象深刻的效果,至少在与之前的文本生成视频技术相比时,效果显著提升。
对于初学者而言,Sora 可以生成多种风格的视频(如真实感、动画、黑白),最长可达一分钟,远超大多数文本到视频模型的时长。
这些视频保持了良好的连贯性,避免了常见的“人工智能怪异”现象,例如物体朝不可能的方向移动。
示例展示
以下是一些 Sora 生成的视频示例:
- 中国龙年舞龙的视频生成。

- 输入提示:加州淘金热时期的历史镜头。

- 输入提示:玻璃球的特写视图,里面有一个禅宗花园。

- 输入提示:一位 24 岁女性眨眼的极端特写。

- 输入提示:穿过东京郊区的火车窗外的倒影。

- 输入提示:赛博朋克背景下机器人的生活故事。

技术细节
在 Sora 推出后,OpenAI 迅速发布了技术报告,探讨了视频数据生成模型的大规模训练。研究人员在可变持续时间、分辨率和宽高比的视频和图像上联合训练了一个文本条件扩散模型。Sora 的最大模型能够生成长达一分钟的高质量视频。
OpenAI 认为,扩展视频生成模型是构建物理世界通用模拟器的一条有前途的途径。

视觉数据转为 Patches
OpenAI 从大型语言模型的成功中汲取灵感,采用了将视觉数据转化为统一表示的方法。Sora 使用视觉 patches 作为训练生成各种类型视频和图像的有效表示。

视频压缩网络
OpenAI 训练了一个降低视觉数据维度的网络,将原始视频作为输入,并输出在时间和空间上压缩的潜在表示。Sora 在这个压缩的潜在空间中接受训练,生成视频。
时空潜在 patches
给定一个压缩的输入视频,OpenAI 提取一系列时空 patches,充当 Transformer 的 tokens。这一方案同样适用于图像,因为图像可视为单帧视频。
用于视频生成的缩放 Transformer
Sora 是一个扩散模型,能够根据输入噪声 patches 和文本提示等调节信息,预测原始的“干净”patches。Sora 的扩散 Transformer 在各个领域表现出色。

可变的持续时间,分辨率,宽高比
Sora 的训练方法允许其生成不同分辨率和长宽比的视频,提供了更大的灵活性。

语言理解
Sora 的训练需要大量带有相应文本字幕的视频,研究团队将 DALL・E 3 中的重字幕技术应用于视频生成。
以图像和视频作为提示
Sora 还可以使用已有的图像或视频作为输入,执行各种图像和视频编辑任务。
局限性讨论
尽管 Sora 展现了许多能力,但仍存在局限性,例如无法准确模拟某些物理现象。官方主页列举了该模型的其他常见失效模式。

Sora 的能力证明了持续扩大视频模型的规模是一个充满希望的方向,未来将助力物理和数字世界的更精确模拟。