前言
去年下半年,Cursor 的热潮席卷而来,让许多对编程一无所知的小白也能轻松创建自己的网站和应用程序。这一现象引发了独立开发的热潮。
然而,每月 20 美元的费用并不便宜。这时,可以考虑使用 Cline、Aider、Composer + Continue 等插件,结合其他大型模型后端,来实现类似的效果。
AI 编程的两种模式
AI 编程目前主要有两种玩法,简单介绍如下:
- 全自动模式(如 Cline、Aider 等工具):用户只需口述需求,AI 即可生成代码,适合小项目,比如制作单页网页或编写命令行工具。不过,目前技术尚不成熟,复杂项目容易出现问题。
- 半自动模式(如 Copilot 等经典工具):用户与 AI 共同编写代码,用户掌控方向,AI 在旁协助补全代码,相当于副驾驶随时递工具。
注意:无论是哪种模式,生成的代码都不应直接照单全收!建议使用 Git 等版本控制工具,频繁提交并对比每次 AI 修改后的代码,以便及时发现问题,避免代码混乱。这是使用 AI 编程的保命小技巧。
Cline 的问题
网上有传言称 Cline 非常消耗 token(使用大型模型需付费,费用根据消耗的 token 数量计算)。我尝试后发现,确实如此,甚至在一个页面未完成时,我充入的 20 元 token 就已用尽。
使用本地部署的 DeepSeek 模型
我尝试使用 Cline 自动生成代码,但发现花费过高,不如自己动手。上次我部署了 DeepSeek 的蒸馏模型(原版 671B,其他模型均为 llama/qwen 等开源模型的蒸馏版本),效果还不错,可以作为 Cline 的后端。
遇到的问题
然而,在默认配置下,Cline 无法正常使用,系统会提示:
Cline is having trouble…
Cline uses complex prompts and iterative task execution that may be challenging for less capable models. For best results, it’s recommended to use Claude 3.5 Sonnet for its advanced agentic coding capabilities.
这个提示的根本原因在于 Cline 的工作模式,通常需要模型具备较强的“代理式”推理、分步骤思考以及对复杂指令的理解和执行能力。相对而言,一些开源大模型(如 DeepSeek-R1 14B)在链式推理、代码解释或复杂上下文推断上可能不够完善,导致在 Cline 这样的多回合 Agentic 插件下容易出现问题。
Cline 的交互流程如下:
- 生成复杂的 Prompt:Cline 根据用户指令生成带有代理特征的复杂提示,包含“你是谁”“你的目标是什么”“你需要如何自省、复盘”等信息。
- 多回合迭代思考:模型多次迭代思考,将每次思考的内容和输出用于生成后续提示,从而不断优化解决方案。
- 提示不兼容:如果模型无法很好地遵循或记住这些多回合提示,或对指导指令理解不准确,就会出现答非所问、上下文混乱等情况,Cline 会侦测到这些现象并报错。
问题的核心在于默认的上下文长度(Context Length)过小,而 Cline 插件需要保留较多的多轮对话上下文,导致模型无法处理足够长的提示,从而出现 “Cline is having trouble…” 的提示。
在坚持使用 Ollama 的情况下,只能通过调整上下文长度来解决这个问题。
调整上下文长度
上下文长度(Context Length)指的是模型在一次推理过程中能记住并处理的 Token 数量上限(可以简单理解为模型的“记忆容量”)。如果这个容量不足,当给模型多轮指令或大段文本时,后续部分会被截断或遗忘,导致任务无法完整理解和执行。
许多开源模型初始设置的上下文窗口往往是 2K、4K,如果 Cline 生成了长 Prompt 或者与其多次对话累积了很多历史信息,原先的 4K 上下文就容易不足。
在 Ollama 中创建带有大上下文长度的模型镜像
创建一个名为 deepseek-r1-14b-32k.ollama(文件名自定)的文件,放置位置无所谓,只要命令行能找到该文件即可。
内容大致如下:
FROM deepseek-r1:14b
PARAMETER num_ctx 32768
然后使用 Ollama 命令行将该文件转为新的模型。例如:
ollama create deepseek-r1-14b-32k -f deepseek-r1-14b-32k.ollama
完成后,相当于你拥有一个带 32k 上下文窗口的 DeepSeek-R1 14B 模型副本。可以使用 ollama list 验证一下:
$ ollama list
NAME ID SIZE MODIFIED
deepseek-r1-14b-32k:latest 6ecc115f8ae2 9.0 GB 1 second ago
deepseek-r1:14b ea35dfe18182 9.0 GB 21 hours ago
下次在 Cline 中,将模型切换到 “deepseek-r1-14b-32k” 就可以使用 32k 的上下文容量,避免因上下文不足导致的中途报错。
映射 Ollama 服务到本地
为了让本地能调用,需要使用 SSH 隧道转发:
ssh -L 11434:localhost:11434 用户名@服务器地址 -p 端口
配置 Cline 插件
点击右上角的齿轮按钮,在 API Provider 选择 Ollama,模型选择我们刚才创建的 deepseek-r1-14b-32k。
设置完成后点击「Done」保存。
火力全开写代码
我让 AI 制作一个「新年祝福生成器」,在提示词中详细描述设计细节,以减少后续修改次数。
输入提示词后,代码开始自动生成。
完成后发现有标红的警告,别担心,AI 会根据提示信息自动修改。
几个显卡都在运行,Ollama 的调度真是神奇。
实现效果
生成的代码只能说一般,DeepSeek-14B 受到模型参数规模的限制。首先出现了以下代码:
距离春节还有 {new Date().getDaysLeftToChineseNewYear()} 天
但却没有定义这个原型扩展方法。同时,它对 Tailwind CSS 的认知有限,背景颜色并未生效。
在我手动修复 bug 后,运行的页面如下:
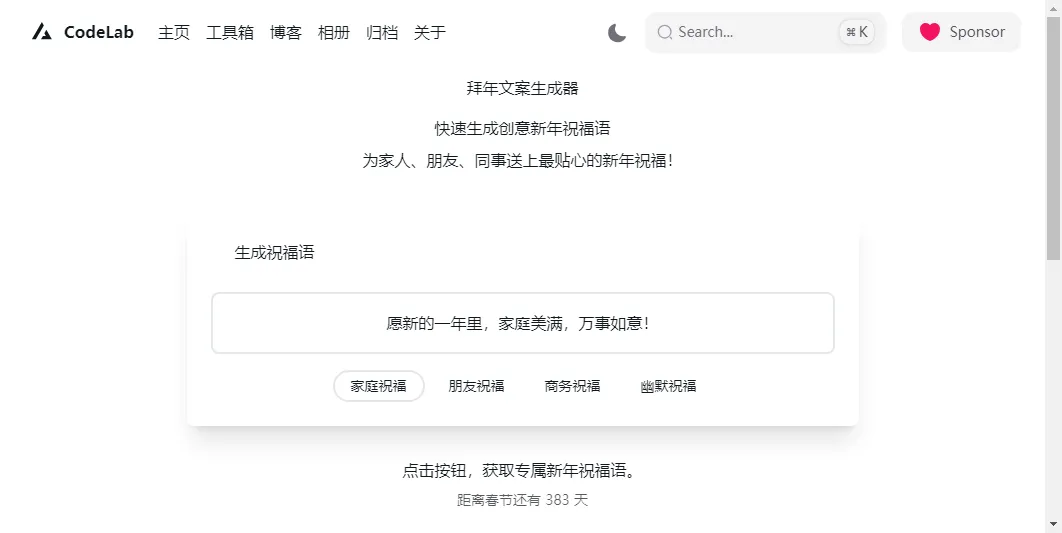

但不能说 DeepSeek-14B 的代码能力完全不行,可能是因为 Cline 插件的上下文太长。我直接与模型对话,同样的需求,生成的代码直接就能运行。
部署 LocalAI(可选)
LocalAI GitHub
LocalAI 充当一个兼容 OpenAI API 协议的网关,对外提供 /v1/xxx 路由(如 /v1/completions、/v1/chat/completions)。
- 你可以用任何支持 OpenAI API 的客户端(如 Python
openai库、LangChain 或各种开源/商用工具)去调用 LocalAI 的地址。 - LocalAI 后台会在本地加载 .bin 或 .gguf 模型,并用 CPU 或 GPU 进行推理,将结果以 OpenAI 兼容的 JSON 格式返回给客户端。
由于我这次使用的 Cline 插件支持直接调用 Ollama,所以不再部署 LocalAI,有兴趣的同学可以自行尝试。
参考资料
小结
勉强能用,Cline 需要消耗的 token 确实很多,我下次会尝试其他插件是否有所改善。